A Decisionist Model of Slavic Morphology
Danko Šipka
1. Introduction
It can be argued that representing certain Slavic inflections as decision trees might enhance both the learning and computational processing of such languages. The word "decisionist"or "decisionism" is meant to be a post-modernist joke having a background consisting of countless linguistic "isms".
Because the Slavic inflections modeling project (which will ultimately provide complete data) remains in its initial stage , of necessity, I will focus on presenting some of the basic ideas, a general overview and, to a smaller extent, concrete experimental data which will be greatly expanded upon in the future
2. Decision Theory and Language
In its broadest sense, a decision can be defined as any act of selection among several possible options. In recent decades there has been numerous works both describing and formalizing the entire decision making process. Such works have primarily been accomplished in psychology where conscious decision making is analyzed and game theory where research is based upon the interrelation and interaction of two or more players. Both fields use such criterion as utility, risk, cost-benefit ratio, etc. More about these approaches can be found in Morrow (1994), Keeney (1996), Kozielecki (1995), von Winterveldt and Edwards(1986).
In the use of language, some situations embody conscious decisions involving the person one is communicating with -- the other player as it were. A situation where one must consciously choose an honorific or gratuitous form of address is a typical example of a game theory type of decision making. However, in the most cases, such decisions are unconscious and fail to take into account the other player, or, to be more precise, the other player is ultimately irrelevant in such decision makiing.
In Slavic morphology,one normally and unconsciously chooses a form of address from an array of possible forms, doing so in such manner that the interlocutor does not influence the choice. Nevertheless, there are situations in foreign language teaching where this theory operates very differently; where the Slavic language student consciously chooses a form as the result of interactions with his or her tutor. Similarly, decisions made by computer programs about forms of inflected Slavic lexemes can also be the result of a conscious decision made by the software author or programmer.
The first goal of this project is to present some Slavic morphological rules as the result of sequential decisions involving risk. The idea is that such modeling can enhance all such situations where decisions about Slavic inflection forms must be made. This task is practical in nature and the ideas and resources used are well known: a. form data from traditional grammars, b hierarchies used in linguistics to classify data, c. decision flowcharts from psychology and computer science
The idea behind this aspect of the project is very simple – to describe the broadest possible range of Slavic morphological forms using a minimal means of description. Needles to say that being parsimonious is one of the crucial requirements of any scholarly research.
The second goal is to develop data by asking the following questions: a. What is the best way to model decision process? b. Do native speakers choose Slavic inflection forms as a result of sequential decisions?
As one can surmise, such a task is laborious because in order to answer these questions one requiresextensive experimental data.
In the next part of this paper I will outline the way in which Slavic morphology is described in the most commonly used grammars and then present solutions for the first goal of the project as well as experimental data related to its second goal.
3. Descriptions of Slavic Morphology
Traditionally, Slavic morphology is described in one-level default and exception style, while some newer approaches have abandoned thisdefault-exception distinction. In other words, traditional Slavic morphological description consists of classifying linguistic material without establishing a clear hierarchy of the criterion used in such classification. If one were to take a typical textbook chapter concerning those situations where Slavic nouns contain a number of different endings, then, one could compile a list of descriptive endings used with which nouns. Additionally, such description would contain numerous narrative pseudo-statistic elements as "mostly", "some" etc., which are not highly informative. These narrative elements are eliminated in several recent approaches such as Зализняк 1987 and Silić 1997 But even here one will not see the use of hierarchy as a classification criteria. This is unfortunate because such could be used in modeling and/or choosing appropriate morphological paradigms as part of the decision making process.
The key issues of modeling morphological data vis-ŕ-vis decision-making trees will be presented using the example of the adjec
tive comparison paradigm. The first step in reorganizing the material from the traditional morphological description is to determine the terminal nodes of a possible decision tree. Simplifying this to a certain degree, one can define the following terminal nodes for Serbo-Croatian, Polish and Russian in turn (S = positive stem):
Serbo-Croatian
|
no comparison |
comparison exists |
|
srpski:0 |
supletive stem |
non-supletive stem |
|
|
dobar:bolji |
S+ši |
S+iji |
S+i |
|
|
|
lak:lakši |
nov:noviji |
full stem |
reduced stem |
|
|
|
|
|
brz:brži |
dalek:dalji |
Polish
|
no comparison |
comparison exists |
|
polski:0 |
analytic comparison |
synthetic comparison |
|
|
interesujący:
bardziej interesujący |
supletive stem |
non-supletive stem |
|
|
|
zły:gorszy |
S+ejszy |
S+szy |
|
|
|
|
łatwy:łatwiejszy |
full stem |
reduced stem |
|
|
|
|
|
stary:starszy |
daleki:dalszy |
Russian
|
no comparison |
comparison exists |
|
русский:0 |
analytic comparison |
synthetic comparison |
|
|
старательный:более старательный |
supletive stem |
non-supletive stem |
|
|
|
плохой:
хуже |
S+ше |
S+ee/ей |
S+e |
|
|
|
|
старый:
старше |
умный:
умнее |
full stem |
reduced stem |
|
|
|
|
|
сухой:суше |
близкий:
ближе |
Table 1
Table 1 illustrates the terminal nodes of the decision making process. The task of modeling the process consists of determining both the decision criteria and in which order they are used to direct each adjective to its node. In other words, the decision making process can be viewed as a set of paths which the adjectives of certain languages must pass before arriving at their correct terminal nodes.
The mathematical formula required to determine the minimal number of features (B) in order to distinguish a number of elements (N) can be written as :
B=ceiling(logarithm(N))+1
In an ideal case, one would therefore need only three features (or three binary nodes) to account for six Serbo-Croatian, six Polish and seven Russian terminal nodes. However, reality is more complicated. Not only do these features not divide the set of elements into two equal groups (making their consequent, number far from minimal) but their very nature is also different because some of the criteria are only information that a certain lex
ical unit belongs to a certain list. Approaches like Зализняк 1987 and Silić et al. 1996 (mentioned previously) extend this list-of-exceptions principle to the entire paradigm. This is of little use to us because such requires each lexical unit to have a specific label
and this borders on information overload.
Let's take a Serbo-Croatian example to see how these criteria (non-terminal nodes) can be reduced. First, one has to separatethe criteria which can be inferred from available grammars. These are presented in the Table 2:
|
|
terminal node |
criterion |
|
1. |
no comparison |
semantic criteria (relative adjectives, full feature...) |
|
2. |
supletive stem |
list of exceptions |
|
3. |
S+ši |
list of exceptions |
|
4. |
S+i |
phonological criterion (long one-syllable stems) |
|
5. |
S+i |
list of exceptions (short one-syllable stems) |
|
6. |
S+i |
list of exceptions (two-syllable stems) |
|
7. |
reduced(S)+i |
list of exceptions (most stems ending in -ok, -ak, -ek) |
|
8. |
S+iji |
everything else |
Table 2
If the above criteria are applie
d, the "centipede" decision flowchart can be created. This, however, is only the first step in modeling the decision making process. The default is established vis-ŕ-vis the most common form as opposed to the "regular" form. That, in morphology, "regular" does not mean " most common" is clearly exemplified in the Serbo-Croatian -et- neuter noun stems where more than 70% of such nouns (extracted from the 80.000 Serbo-Croatian NeuroTran® dictionary entries) has "irregular" -ad collective plural, as in pile-pilad, tele-telad, etc. This type of default setting optimizes the decision making flowchart to an extent but the model is still low efficiency due to the fact that the nodes are not hierarchically organized. Therefore, additonal transformations of the model are needed to optimize it.
The first transformation of the "centipede" is to merge the nodes which are used by the small number of adjective stems. Consequently, we can merge nodes 2 and 3 because the ending -ši is attached to only three stems and it can be appended to the suppletive stems category. The second transformation consists of establishing a hierarchy while, at the same time, setting defaults for each level of the hierarchy. One of the possible results of this process is presented in the Figure 1
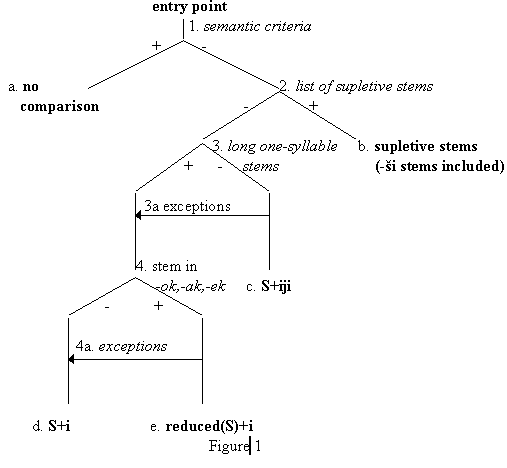 The intention is that at each level of hierarchy (in each of the sequential decisions) there is default for those elements which have a definitive value as well as a list of exceptions which redirects those cases which fail to meet the criterion in question.
The intention is that at each level of hierarchy (in each of the sequential decisions) there is default for those elements which have a definitive value as well as a list of exceptions which redirects those cases which fail to meet the criterion in question.
As mentioned previously, this is only one way of ordering decisions. Its purpose is merely to illustrate the reasoning behind making formalizations. Theoretically, we could first ask if the stem ends in -ak,-ok,-ek, then, check to see if it is long or short, etc. However, even in a setting of reduced information, one can find at least two useful applications of this type of modeling – foreign language teaching and computational linguistics. In foreign language teaching, the decision making process is used with a"human interface" and exceptions should be included gradually. A reduced decision making tree for a Serbo-Croatian comparison paradigm (with its human interface) can have the following form:
- Learn the list of supletive stems and, if adjective is one of these, use the supletive form.But if it is not:
- check if the stem has one syllable and a long vowel, if so, palatalize the last consonant and add -i. If the stem does not belong to this category, use -iji
This simple decision making heuristic gives the right form of comparative in the vast majority of cases. This teaching process can include further nodes and thus reduce the margin of error. Exactly how this is accomlished is dependent on the concrete second language teaching approach (see the review of this in McLaughlin 1987).
In computational linguistics, this solution is useful because it uses "defaults" on all levels of the hierarchy It only requires additional information for the rare exceptions. This provides substantial time savings in the preparation of any lexical module for any MT system. For example, in the NeuroTran® system (1997), most of the adjectives appear as: učen,a,o; glup,a,o;
Their basic corresponding comparative rule is:
|
Rule |
Explanation |
Example |
|
COMPARATIVE; |
Rules to generate the comparative paradigm are as follows |
|
|
O1=(1->','); |
The stem is the sequence of characters in front of the comma |
učen, glup |
|
O1=IF NUMSYL(O1)<>1 THEN O1+ij ELSE SCPAL(O1); |
If the number of syllables is different from one, add "ij" to the stem, otherwise palatalize the last consonant |
učenij, gluplj |
|
SINGULAR; |
Singular forms of the comparative are |
|
|
MASCULINE; |
in masculine gender |
|
|
NOM=O1+i; |
add "i" to get nominative |
učenij+ i, gluplj+i |
|
|
[...] |
|
Table 3
The adjectives this rule does not account for will simply have their comparative form written in the dictionary entry, as in: zao,zla,zlo,gori; tijesan,sna,sno,tješnji;
All this can be applied to both the Polish and Russian comparative paradigms and numerous other segments of morphology. However the material herein presented is sufficient to illustrate some key ideas.
The questions to be asked now is how to determine: a. what is the optimal content of the decision node? b. what is the optimal number of nodes? c. how should the decision nodes be ordered? There are two basic sources of data which can be used for these purposes. One is frequency count from the representative corpora for a given language. One might want to organize the decision making tree in such a manner so that the minimal number of nodes cover the most frequent cases. The second source data comes from the psycho-linguistic experiments in learning foreign language forms. Here, we can hopefully determine which specific node order makes it easier for a student to acquire a set of forms.
5. Decisionist Model - Experimental Data
Turning to the second task of this project -- asking if native speakers of Slavic languages really generate morphological forms as part of sequential decisions -- we want demonstrate how this can investigated by using the example of the genitive endings of Polish nouns. Using the previously presented pattern and with certain degree of simplification, the Polish genitive ending decision making tree can be modeled as follows:
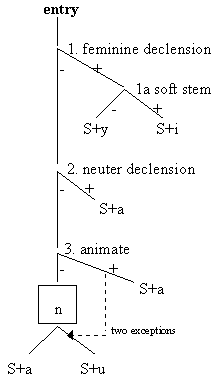 Figure 3
Figure 3
The major point is that -- in the case of inanimate masculine nouns -- one first needs to pass a series of decision nodes (marked herein as n) In the case of feminine, neuter and animate masculine inflection the situation is straightforward and the number of decision nodes is substantially lower. If it is true that native Polish speakers generate agenitive ending in a series of decisions, we would expect that reaction times to the items in nodes 1-4 are lower than the reaction times to n nodes. That is to say, one will recognize and/or generate forms such as gazety faster than such forms as
kłopotu.
A simple psycho-linguistic experiment has been conducted in order to check if the decision-making tree previously exhibited has anything to do with the way people process this kind of information. The subjects were presented with nominative choices along with correct genitive forms of different Polish nouns and asked to verify if the forms were correct or not. The forms belonged to the lexemes split into four groups: non-masculine nouns: 1 feminine nouns ending in -a, 2 declinable neuter nouns; masculine nouns: 3 inanimate masculine nouns with consonant ending, 4 animate masculine nouns with consonant ending
It has been conjectured that there will be higher reaction time for masculine nouns than for non-masculine nouns that the overall reaction time to inanimate masculine nouns will be high
er than the reaction time for animate masculine nouns. The lexemes from the four groups were also balanced vis-ŕ-vis frequency and length. The other possible variables (digraphs, alternations, etc.) were also eliminated. The nouns used in the experiment are:
|
non-masculine nouns |
Coefficient F |
# of chr |
|
1 feminine nouns ending in -a |
|
|
|
sobota |
73 |
6 |
|
gazeta |
64 |
6 |
|
ustawa |
59 |
6 |
|
wina |
47 |
4 |
|
reforma |
39 |
7 |
|
kolejka |
32 |
7 |
|
barwa |
22 |
5 |
|
farba |
11 |
4 |
|
powłoka |
9 |
7 |
|
oliwa |
7 |
5 |
|
TOTAL 11 |
363 |
57 |
|
2 declinable neuter nouns |
|
|
|
słońce |
93 |
6 |
|
biuro |
81 |
5 |
|
pismo |
56 |
5 |
|
wino |
32 |
4 |
|
srebro |
26 |
6 |
|
piwo |
21 |
4 |
|
górnictwo |
21 |
9 |
|
następstwo |
19 |
10 |
|
wapno |
8 |
5 |
|
wesele |
6 |
6 |
|
TOTAL 12 |
363 |
60 |
|
masculine nouns |
|
|
|
3 inanimate masculine nouns ending in consonant |
|
|
|
teatr |
92 |
5 |
|
kłopot |
68 |
6 |
|
dokument |
55 |
8 |
|
park |
32 |
4 |
|
kryzys |
26 |
6 |
|
wykład |
26 |
6 |
|
protest |
22 |
7 |
|
umysł |
22 |
5 |
|
monopol |
11 |
7 |
|
kiosk |
8 |
5 |
|
TOTAL 21 |
362 |
59 |
|
4 animate masculine nouns ending in consonant |
|
|
|
rolnik |
80 |
6 |
|
premier |
75 |
7 |
|
kandydat |
62 |
8 |
|
oficer |
58 |
6 |
|
delegat |
39 |
7 |
|
partner |
22 |
7 |
|
fizyk |
11 |
5 |
|
muzyk |
8 |
5 |
|
kowal |
7 |
5 |
|
kozak |
6 |
5 |
|
TOTAL 22 |
368 |
61 |
Table 4
Fity normal adult Polish subjects were asked to confirm if the genitive form of the nouns from the Table 4 is correct or not. The reaction time of the decisions was recorded and the results presented in Table 5
|
Group |
Mean Reaction t 1/100 sec |
Factor |
Dependent Variable |
Sign. |
|
1 |
201,92 |
1,2,3,4 |
reaction t |
p=,0000 |
|
2 |
204,10 |
1(=12),2(=34) |
reaction t |
p=,0000 |
|
3 |
247,05 |
1,2 |
reaction t |
p=,7977 |
|
4 |
234,37 |
3,4 |
reaction t |
p=,2136 |
Table 5: One-way ANOVA results
The results demonstrate that there is a statistically significant difference between the reaction time to differentiate between feminine/neuter nouns and masculine nouns. There can be various reasons for this including those mentioned earlier. However, further experimental work is needed to make any definitive claim.
6. Acknowledgements
I would like to express my thanks to James Connolly for proofreading this paper and the Alexander von Humboldt-Stiftung that made it possible for me to work on the usage label network.
References
- NeuroTran®, MT system by Translation Experts Ltd., 1997
Barić, E. et al.
Hrvatska gramatika, ŠK, 1995
Grzegorczykowa, R et al. Gramatyka współczesnego języka polskiego - Morfologia, PWN, Warszawa, 1984
Keeney, R. L. 1996. Value-focused thinking. A Path to Creative Decisiomaking. Harvard:Harvard University Press
Kozielecki, K "Podejmowanie decyzji", w: T. Tomaszewski Psychologia ogólna, PWN, Warszawa, 1995
McLaughlin, Barry. Theories of Second Language Learning, Rouglege, 1987
Morrow James D. Game Theory for Political Scientists, Princeton, 1994
Silić, J. et al. Hrvatski računalni pravopis
, Zagreb, 1996
Валгина, Н.С и др. Современный русский язык, ВШ, Москва, 1966
von Winterveldt, D. and W. Edwards.1986 Decision Analysis and Behavioral Research. Cambridge: Cambridge University Press
Зализняк, А.А. Грамматический словарь русского языка, РЯ, Москва, 1987
Danko Šipka (d.sipka@tranexp.com)