Video-based Face Recognition
Rama Chellappa, University of Maryland, College Park
Pavan Turaga, Arizona State University
September 23rd 2012
Video-based Face Recognition
Rama Chellappa, University of Maryland, College Park
Pavan Turaga, Arizona State University
September 23rd 2012

Introduction
Several studies in neuroscience have established that movement of faces is utilized by humans to mitigate the harsh effects of non-optimal viewing conditions, such as low-resolution, occlusion, and low illumination [1]. However, devising computational models that can exploit motion has been much more challenging. This is due to the simultaneous challenges of detection, tracking, motion modeling, and matching. Video-based face recognition holds the promise of enabling more accurate and robust recognition performance. In this tutorial, we present an overview of models and algorithms that address these issues with the hope of fostering further research into this unique problem.
Tutorial Slides (Final Slides will be available after the tutorial)
1.Face tracking and recognition in camera networks, Rama Chellappa Pdf of presentation
2.Manifold models for video-based face recognition, Pavan Turaga
Topics
Joint tracking and recognition of faces using particle filters
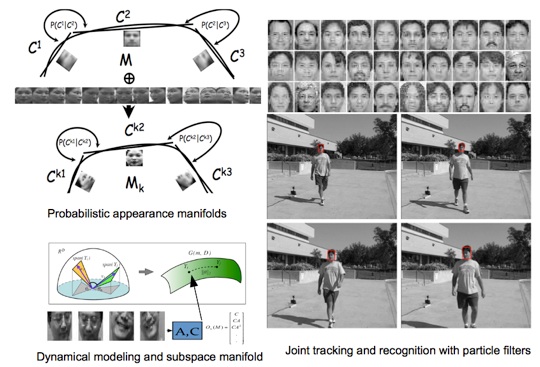
Temporal information in videos can be exploited for simultaneous tracking and recognition of faces without the need to perform these tasks in a sequential manner. There are several advantages in performing these tasks simultaneously. In the tracking- then-recognition framework, estimation of parameters for registration between a test face and a template face, compensating for appearance variations due to changes in viewpoint, illumination etc and voting on the individual recognition results might be an ad hoc solution. By effectively exploiting temporal information, the tracking-and-recognition framework performs all these steps in an integrated manner. We will present a general frameowork using particle filters [3] that can be used for this task.
Manifold models of face appearance
Most face recognition approaches rely on a static model of appearance for each individual subject. The simplest appearance model is simply a static image of the person. Such appearance models are rather limited in utility in video-based face recognition where subjects may be imaged under varying viewpoints, illuminations, expressions etc. Thus, instead of using a static image as an appearance model, a sufficiently long video which encompasses several variations in facial appearance can lend itself to building more robust appearance models. In this context, we will discuss the appearance manifold representation [2] and the shape-illumination manifold [4], and how these manifold models can be used for joint detection, tracking and recognition.
Matching videos using parametric dynamical models
The dynamic signature in the form of idiosyncratic gestures or expressions of the face also play an important role in identifying faces. We will discuss models that can be used to encode such variations and how recognition can be performed using such models. Specifically, we will consider a dynamical-systems approach to model videos of faces. This results in a joint appearance and dynamics-based matching between a probe video to a gallery video. The matching of dynamical models will be presented in-depth using tools from differential geometry and manifold theory [5].
Biographies

Prof. Chellappa has received several awards, including an NSF Presidential Young Investigator Award, four IBM Faculty Development Awards, an Excellence in Teaching Award from the School of Engineering at USC, and two paper awards from the International Association of Pattern Recognition. He received the Society, Technical Achievement and Meritorious Service Awards from the IEEE Signal Processing Society. He also received the Technical Achievement and Meritorious Service Awards from the IEEE Computer Society. At University of Maryland, he was elected as a Distinguished Faculty Research Fellow, as a Distinguished Scholar-Teacher, and received an Outstanding Innovator Award from the Office of Technology Commercialization, and an Outstanding GEMSTONE Mentor Award. He received the Outstanding Faculty Research Award and the Poole and Kent Teaching Award for the Senior Faculty from the College of Engineering. In 2010, he was recognized as an Outstanding ECE by Purdue University. He is a Fellow of the IEEE, the International Association for Pattern Recognition, the Optical Society of America and the American Association for Advancement of Science. He holds three patents.
Prof. Chellappa served as the associate editor of four IEEE Transactions, as a Co-Editor-in-Chief of Graphical Models and Image Processing and as the Editor-in-Chief of IEEE Transactions on Pattern Analysis and Machine Intelligence. He has also served as a co-guest editor for six special issues published by leading journals and Transactions. He served as a member of the IEEE Signal Processing Society Board of Governors and as its Vice President of Awards and Membership. He has served as a General and Technical Program Chair for several IEEE international and national conferences and workshops. He is a Golden Core Member of the IEEE Computer Society and served a two-year term as a Distinguished Lecturer of the IEEE Signal Processing Society. Recently, he completed a two-year term as the President of the IEEE Biometrics Council.

References
[1] O'Toole, A. J., Roark, D., Abdi, H.: Recognizing moving faces: A Psychological and Neural Synthesis. In: Trends in Cognitive Sciences, 6, 261-266 (2002).
[2] Kuang-Chih Lee, Jeffrey Ho, Ming-Hsuan Yang, David J. Kriegman: Visual tracking and recognition using probabilistic appearance manifolds. Computer Vision and Image Understanding 99(3): 303-331 (2005)
[3] Zhou, S., Krueger, V., and Chellappa, R.: Probabilistic recognition of human faces from video. In: Computer Vision and Image Understanding (CVIU) (special issue on Face Recognition), Vol. 91, pp. 214-245, 2003.
[4] Arandjelovic, O. and Cipolla, R.. Face recognition from video using the generic shape-illumination manifold. In: Proc. 9th European Conference on Computer Vision, Graz (Austria) volume LNCS 3954, pages 27-40, Springer, 2006.
[5] Pavan K. Turaga, Ashok Veeraraghavan, Anuj Srivastava, Rama Chellappa: Statistical Computations on Grassmann and Stiefel Manifolds for Image and Video-Based Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 33(11): 2273-2286 (2011)
Various representations for video based face recognition. Figures courtesy [2,3,5].