Multiple Linear Regression - Model Testing
The following tests should be carried out:
- Tests of parameter significance of all parameters
 0,
1,
2,
...,
k.
These tests can be accomplished also by finding the corresponding confidence intervals.
0,
1,
2,
...,
k.
These tests can be accomplished also by finding the corresponding confidence intervals.
- Test of significance of the overall regression.
- Test of the Ordinary Least Squares Assumptions (OLS).
Parameter Tests
All parameter tests are t-tests of the same form as in simple linear regression. With k+1 parameters there are k+1 t-tests to be conducted, one test for each variable j from 0 to k:
- H0: j=0
- H0: j
 0
0
- Assume the level of significance
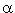
- Evaluate the test statistic Tcalc:

- Determine the critical region (rejection region)
(Degrees of freedom for the t-distribution,
 =n-k-1, and
critical region Tcalc <
-t/2,
or Tcalc >
+t/2,
.
=n-k-1, and
critical region Tcalc <
-t/2,
or Tcalc >
+t/2,
.
- Conclusion:
If Tcalc falls into the critical region, then reject H0, and conclude thatj is significantly different from
zero (i.e. significant). Otherwise accept H0, and conclude
that j is not significantly different
from zero, (i.e. not significant).
Parameter Confidence Intervals
As an alternative to the above parameter tests you may want to find a confidence interval for each parameter. All parameter confidence interval formulae are of the same form. They can be derived from the T-test statistic.

Note: Here you first simply look at the signs. If the confidence interval left-hand side sign is negative and the right-hand side sign is positive, then zero is included in the interval. Hence, the parameter is not significant, because it may be zero. If, on the other hand, the left-hand side- and right-hand side signs are the same, either both negative or both positive, then zero is not included in the interval, and the parameter is significant (significantly different from zero).
Test of the Significance of the Overall Regression
This is an F-test like in simple linear regression. The test uses
the total variability SST in the data. This variability is divided
into variability due to regression SSR and variability due to
randomness SSE. If all variability in the data is only randomness
then SST=SSE. If all variability in the data can be accounted for
by the relationship between the dependent variable and the independent
variables then SST=SSR. Because some randomness will exist in the
data, therefore SST=SSR+SSE. Now two independent estimators of
error variance  2
are obtained, one using the SSR and the other using the
SSE.
2
are obtained, one using the SSR and the other using the
SSE.
The error variance estimator from SSR becomes

The error variance estimator from SSE becomes

It can be shown that both estimators are unbiased if the data contains only randomness and there is no relationship between the dependent variable y and the independent variables xj, i.e.

and the random variable

follows the F-distribution. However, if there is a relationship between the dependent variable and the independent variables then the estimator s12 is a biased estimator

and the F- random variable does not follow the F-distribution. For significant regression one hopes that s12 would be a biased estimator, and hence, that significant amount of variability in the data would be contained in the SSR.
Note: You may recall that an estimator is said to be unbiased if the expected value of the estimator is the population parameter. That's all what the notation above stands for (E(...)= ...). You don't need to worry about this here. It is just to remind you why and how we came up with the formulae.
Steps for the Overall Significance Test using the ANOVA Approach
- H0: The regression is not significant
- H0: The regression is significant
- Assume the level of significance
- Evaluate the test statistic Fcalc:

- Determine the critical region (rejection region)

- ANOVA Summary Table

Note: This type of an ANOVA summary table is part of regression output of many software capable of statistical analysis including MS Excel.
- Conclusion
If Fcalc >f
,
1,
2
=f,(k,n-k-1)
then conclude that there is a significant amount of regression explained
by the model.
Test of the Ordinary Least Squares Assumptions (OLS)
This test is carried out as in simple linear regression by plotting the
residuals ei=yi-
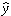 i against the estimated
(or fitted) values
I.
Each residual provides a point estimate for the error. Again, we are looking
for a horizontal band of dots with about constant width, centered around
zero for increasing
values, and not forming any patterns
or clusters.
i against the estimated
(or fitted) values
I.
Each residual provides a point estimate for the error. Again, we are looking
for a horizontal band of dots with about constant width, centered around
zero for increasing
values, and not forming any patterns
or clusters.
Note: For practise, please repeat manual computations for a multiple linear regression case with two independent variables, and create the corresponding MS Excel table (with formulae). This will help you eliminate any and all 'magic' from regression.